
I recently built an API to automate Oracle database installation and patching on Linux containers running on local and cloud infrastructure. This would normally involve pulling media from a local repository, with all required install files and patches pre-staged. However, this project wasn't limited to predefined configurations. The API specification allowed users to pass a list of patches at runtime. The solution needed to automatically download anything not already in the local software catalog.
To download a patch from MOS, I needed to automate these steps:
-
Log into the site and save a cookie.
-
Find the download URL for the patch.
-
Access the URL using the cookie file.
This didn't seem too difficult. Several blog posts describe how to authenticate with My Oracle Support and download patches. Unfortunately, some rely on manual authentication with MOS on one host to generate the cookie file, then copy the cookie to the automation machine. This isn't acceptable for a fully automated solution or in multi-user environments. Login needs to be automatic, secure, and independent of the API code.
The other documented solutions I found used wget. Linux containers use minimalist filesystems for reduced footprint and attack surface on the container hosts. wget isn't part of the limited container packaging, but curl is. It didn't make sense to install wget just to handle patching with curl already present.
I also assumed the download URL would fit a standard pattern. All I'd have to do was substitute the patch and platform identifiers into the URL. I was wrong!
My Oracle Support Login
Before downloading patches from MOS, the session needs an authentication token in the form of a cookie. We'll pass a MOS user ID and password to a URL to get the cookie. It's the automation equivalent of entering your credentials here.
Prior to working on this project, I didn't use curl for anything much beyond simple file downloads, but I knew I needed something like this:
curl "https://updates.oracle.com/Orion/Services/download" <login credentials>
<a place to put the cookie>
-u/--user flag in curl passes a username and password at the command line. But, supplying credentials as plain text is… very bad. The --digest option enables digest authentication and prevents curl from sending credentials over the wire as plain text. However, this information is still visible in command history and, on a shared Linux system, available to anyone able to view active processes on the system. The -K/--config option instructs curl to read command-line options from a file. This is a better option, but files that aren’t understood within regular security postures (like keys saved in special directories) are subject to being overlooked.--netrc and --netrc-file options blend a bit of all three. They tell curl to use a file on the local machine, typically $HOME/.netrc (or $HOME/_netrc on Windows systems) for authentication. The credentials are sent securely to the remote site and aren't visible to other users on the system. The .netrc file is a well-known standard and supports logins for multiple sites. Login information for a site is recorded as three lines of key-value pairs:machine login.oracle.com
login username@email.com
password MySup3r$ecre7Pa$$w0rd
With the --netrc option, curl looks for a file named .netrc in the home directory. The --netrc-file option takes a path and filename for the file. I elected to use the latter since it allows more flexibility should I need to specify a non-default location. In curl, cookies are stored in the (appropriately named) Cookie Jar, passing the cookie path to the --cookie-jar flag. The evolving command:
curl "https://updates.oracle.com/Orion/Services/download" --netrc-file /netrc_path/netrc_file --cookie-jar /cookie_path/cookie_file
-
-s/--silent: Makescurlsilent. -
-S/--show-error: Outputs error messages in silent mode. (In silent mode,curleven fails silently.) -
--connect-timeout 3:curlfails if connections take longer than three seconds. -
--retry 5: Retries a failed transfer five times.
The final command for authentication and cookie creation:
curl -sS --connect-timeout 3 --retry 5 "https://updates.oracle.com/Orion/Services/download" --netrc-file /netrc_path/netrc_file --cookie-jar /cookie_path/cookie_file
MOS Patch Download URLs
I assumed patch downloads would follow a pattern: https://updates.oracle.com/something, with variables for the patch ID and platform ID, (like "&patch_id=6880880&platform_id=226P") embedded in the URL string. I reasoned that once I found that pattern, I could simply substitute the patch ID and get any patch I needed. Unfortunately, nothing's easy with Oracle. The download URL does not follow consistent patterns and usually doesn't include the patch ID at all. Instead, they reference a file name, file_id, and aru that don't appear to relate to the patch ID itself. For instance, the URL for the latest 19c and 21c OPatch downloads are (in part):
https://updates.oracle.com/Orion/Download/process_form/p6880880_190000_Linux-x86-64.zip?file_id=112014090&aru=24869627&patch_file=p6880880_190000_Linux-x86-64.zip
https://updates.oracle.com/Orion/Download/process_form/p6880880_210000_Linux-x86-64.zip?file_id=112015456&aru=24869477&patch_file=p6880880_210000_Linux-x86-64.zip
I discovered I needed the file_id and aru to construct a download URL. Some older patches required additional information or used entirely different links. Fortunately, the download URL for any patch is available through the patch search function, which does follow a meaningful structure based on the patch ID:
https://updates.oracle.com/Orion/SimpleSearch/process_form?search_type=patch&patch_number=<PATCH ID>&plat_lang=<PLATFORM ID>
Platform IDs are standard and published by Oracle (it's 226P for Linux x86-64). I only need to substitute the patch ID. The result contains the download URL in its raw HTTP, normally sent to a browser, as the link under the "Download" button.
For the automation, I captured the search page for a file with the following pseudo code:
curl -sS --connect-timeout 3 --retry 5 -L --location-trusted "https://updates.oracle.com/Orion/SimpleSearch/process_form?search_type=patch&patch_number=<PATCH ID>&plat_lang=<PLATFORM ID>" -o <OUTPUT FILE>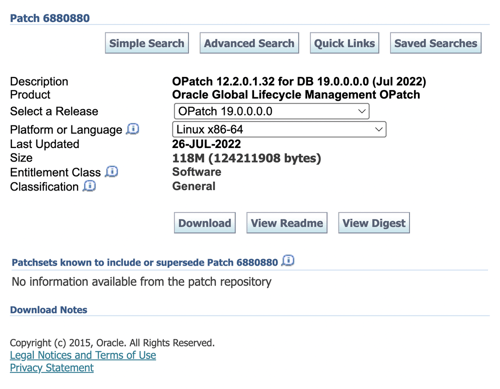
Find the Download URL
Buried somewhere in the output file is the download link I'll use to (finally) get the patch file. The only problem is finding it! After a lot of trial and error, I landed on a search pattern for finding eligible download links in the MOS search results output:
grep -e "https.*$patch_id.*\.zip" <OUTPUT FILE> | sed -e "s/^.*\href[^\"]*\"//g;s/\".*$//g"
For those that aren't comfortable with Linux pattern matching utilities:
-
grep: Search for lines in a file. -
-e: use regular expressions. -
"https.*$patch_id.*\.zip": Look for lines containing a string with "https" followed by one or more characters, then the patch ID, then one or more characters, then ".zip". The dot character in regular expressions means "any character," and the asterisk means "zero or more of the expression before." The dot is a special character in regular expressions. To getgrepto recognize a literal dot or period, prefix it with a backslash, the escape character. -
|: "Pipes" output of the previous command to another. -
sed: A Linux command line editor I'll use to remove everything that isn’t the download URL. -
-e: Use regular expressions. -
"s/^.*\href[^\"]*\"//g;s/\".*$//g": Insed,s/A/B/gmeans, "Find A and replace it with B, globally“ (everywhere it occurs). There are two find/replace operations in this command, separated by the semicolon:-
s/^.*\href[^\"]*\":^is a special character that may have multiple meanings. Here, it means "The start of the line." The dot-asterisk combination, like the one in thegrepcommand, means "one or more characters." The backslashes inside the "find" part of sed designate a group of characters:href[^\"]*". The brackets match one or more specific characters. The closing bracket is followed by an asterisk, sosedlooks for any number of characters matched inside the brackets. But the first character inside the brackets is^, a metacharacter that (in this case) means "not". The backslash "escapes" the quote. Put it together, and it means "anything that's not a quote mark". Taken together, this instructssedto start at the beginning of the line, look for one or more of any character until it hits something that reads href, followed by any number of characters that are not a quote mark. -
//g: Replace the matched string—everything up to the beginning of the URL—with nothing. -
s/\".*$//g": Find a literal quote (\") and then any character, up to the end of the line (.*$) and replace it with nothing (//g) anywhere it appears on the line.
-
Links in HTTP pages are preceded by "href," an equal sign, maybe some white space, and then a quote. This looks for boundaries around a URL and removes what comes before and after, leaving just the link. With it, I can download the patch with curl:
curl -Rk -sS --connect-timeout 3 --retry 5 -L --location-trusted "<URL>" -o <OUTPUT FILE>
I added two new options to thiscurlcommand,-Rk:
-
-R/--remote-time: Check the timestamp of the remote file, and don't download it unless it's newer than anything available locally. This saves the time and effort of downloading files already present on the host but also allows me to get updated versions of a file I do have. It's particularly useful for OPatch. Just because I have OPatch doesn't mean it's current. If other patches in the installation require a newer version of OPatch, the installation fails late in the process. -
-k/--insecure: Causescurlto skip verification of the remote host. I know it's Oracle in this case.
Most readers will likely only need to log in, search for a patch, and determine the correct download link. However, if you’re developing automation, read on!
Did I Download a Patch?
I wanted to include a message in the API output indicating whether the process downloaded a newer version of an existing patch. I decided to use the -w/--write-out option and pass the download size back to the script. I can check the size and report whether something was downloaded and, if so, its size. The curl command is otherwise silent, so the only output is the download size (or an error). I can capture that in a variable:
patch_bytes=$(curl -Rk -sS --connect-timeout 3 --retry 5 -L --location-trusted "<URL>" -o <OUTPUT_FILE> -w '%\n') || error "Error downloading patch <PATCH ID>"
Multiple Links
I ran into some cases where the search page produced multiple matching URLs for a single patch and platform ID. They were typically password-protected or superseded versions. To address those situations, I embedded the URL search string in a for loop.
Convert to a Function
I like writing reusable code. This has applications beyond Docker, so I built it into a function that takes input variables and does the work. (In this version, the file name is known and passed to the function instead of the patch ID.) The patching step using this code sample (more at https://github.com/oraclesean/docker-oracle) runs during the docker build process as the root user and calls the curl commands via sudo, preserving the correct permissions.
downloadPatch() {
local __patch_id="$1"
local __patch_dir="$2"
local __patch_file="$3"
local __platform_id="$"
local __cookie="$"
local __patch_list="$"
local __netrc="$"
local __curl_flags="-sS --netrc-file $__netrc --cookie-jar $__cookie --connect-timeout 3 --retry 5"
if [ ! -f "$__netrc" ]
then error "The MOS credential file doesn't exist"
fi
# Log in to MOS if there isn't already a cookie file.
if [ ! -f "$__cookie" ]
then sudo su - oracle -c "curl $__curl_flags \"https://updates.oracle.com/Orion/Services/download\" >/dev/null" || error "MOS login failed"
fi
# Get the list of available patches.
sudo su - oracle -c "curl $__curl_flags -L --location-trusted \"https://updates.oracle.com/Orion/SimpleSearch/process_form?search_type=patch&patch_number=$\" -o $__patch_list" || error "Error downloading the patch list"
# Loop over the list of patches that resolve to a URL containing the patch file and get the link.
for link in $(grep -e "https.*$__patch_file" "$__patch_list" | sed -e "s/^.*\href[^\"]*\"//g;s/\".*$//g")
do
if [ "$link" ]
then # Download newer/updated versions only
if [ -f "$__patch_dir/$__patch_file" ]
then local __curl_flags="$__curl_flags -z $__patch_dir/$__patch_file"
fi
# Download the patch via curl
local __patch_bytes=$(sudo su - oracle -c "curl -Rk $__curl_flags -L --location-trusted \"$link\" -o $__patch_dir/$__patch_file -w '%{size_dow
nload}\n'") || error "Error downloading patch $__patch_id"
if [ "$__patch_bytes" -eq 0 ]
then echo "Server timestamp is not newer - patch $__patch_id was not downloaded"
fi
else warn "No download available for patch $__patch_id using $link"
fi
done
}
Mounting Secrets
With the download function in place, all that remains is building an image and mounting the secret with a .netrc file from the local environment. Docker secrets are defined in two places: the Dockerfile, and the build command.
The docker build command mounts the secret and makes it available to Docker:
docker build ...
-secret id=netrc,src=~/.netrc
...
This tells Docker to mount a file, ~/.netrc, into the build process with an ID of "netrc". A corresponding RUN instruction in the Dockerfile consumes the secret by its ID, making the mounted file available to the commands called in a RUN operation::
RUN --mount=type=secret,id=netrc,mode=0600,uid=54321,gid=54321,dst=/home/oracle/.netrc ...Breaking down the command:
-
-—mount=type=secret: Mounts a local file as a secret. -
id=netrc: This is the ID of the secret Docker passed from the build command. -
mode=0600,uid=54321,gid=54321: Sets the file ownership and permissions inside the container to theoracleuser (54321) andoinstallgroup (54321). Permissions of 0600 prohibit other users from viewing the file. -
dst=/home/oracle/.netrc: The destination file name inside the container.
The .netrc file from the local host is mounted and available only during the software installation and patching operation. Credentials aren't broadcast as plain text, visible to other users on the system, or part of the repository. The secret file is local for users and, as long as the user running the build has permission to read, available only during the RUN operation. The solution is fully automated and portable across users.
If you try this, I’d love to hear from you, particularly if you encounter any URLs that break either the search conditions or find/replace operations!

SUBMIT YOUR COMMENT