
Spoiler: You’re probably not smarter than the database kernel
Yet Oracle’s locking implementations don’t prevent deadlocks. Deadlocks are a special concurrency condition created when two transactions lock one or more rows needed by the other. Neither session can commit their changes because the other is blocking it—thus the term, “deadlock.”
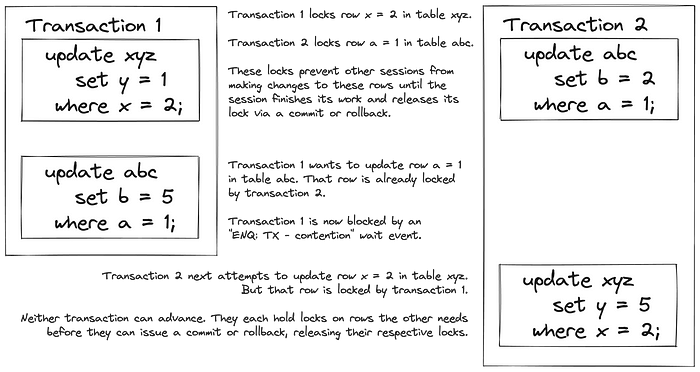
Deadlocking occurs when two transactions lock rows needed by the other. Neither transaction can proceed to commit or rollback its changes because of the lock(s) held by the other.
Deadlocks: Not Oracle’s Fault
When a deadlock happens, Oracle raises an
ORA-60 error and writes it to the alert log, along with the following warning:
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL.
This seems a bit dismissive until you realize that a deadlock is not a database error. It’s a condition caused by a sequence of events in DML statements executed against the database. Oracle’s concurrency mechanisms exist to prevent multiple sessions from simultaneously updating the same objects and introducing unexpected or wrong results.
One reason deadlocks can create such difficult, even devastating problems for relational databases is a disconnect between database administrators and developers. The error message is raised in the alert log—often only visible to DBAs—and rarely reported at the application level. In fact, deadlocked sessions don’t “see” an error because they’re waiting for resources to be released, which is normal (and desirable) behavior for the database!
But an error is an error, and in Oracle PL/SQL, we can create a pragma exception for errors and raise the exception to deal with the situation. Deadlocks are not (pardon the pun) an exception to this rule. So, if we can raise an exception for a deadlock, we can (theoretically) introduce logic to handle deadlocks, perhaps even better than Oracle. After all, if we own the application logic responsible for deadlocks, it makes sense that we would understand best how to resolve deadlocked sessions!
Deadlocking is an application/code issue. You’re better off fixing the cause than implementing workarounds.
Don’t Try This at Home
I recently had a lengthy discussion with a development team dealing with application code causing significant deadlocking on a system. They suggested raising deadlock exceptions in the code. At first, I didn’t think that was possible. I assumed the deadlock would only be visible outside the transaction and couldn’t be caught at the session level. I was wrong—it’s absolutely possible to trap an
ORA-60 deadlock exception.
Despite being possible, it’s probably not a good idea. Each proposed workaround produced new issues requiring more code and testing. Exception handlers can’t address anything outside the codebase, and solutions that don’t anticipate the subtleties of Oracle’s native locking mechanisms are more trouble than they’re worth.
Oracle does concurrency exceptionally well, and deadlocks are a natural result of that. To illustrate the vulnerabilities of an artificial solution, I created a simple stored procedure with a deadlock exception. It initially seems to work, but I’ll demonstrate why this approach is more trouble than it’s worth by showing how easy it is to corrupt data, even with very straightforward code!
Setup the Environment
First, create a sequence, table, and index to represent an application table, then add data:
create sequence t1_seq;
create table t1 (
key number default t1_seq.nextval not null
, val1 number
, session_id number);
create unique index t1_pk
on t1(key);
alter table t1
add constraint t1_pk
primary key (key)
using index t1_pk;
insert into t1 (val1)
select 1
from dual
connect by level < 3;
I’ll also create a logging table to track exceptions raised in the application code, so developers will have a means of identifying how and when deadlocks happen:
create table ora60_log (
err_source number
, err_exception varchar2(10)
, err_code number
, err_date date);
Next, create a procedure that produces deadlocks:
create or replace procedure ora60 (
p_key1 in t1.key%TYPE
, p_key2 in t1.key%TYPE)
as
v_err_code ora60_log.err_code%TYPE;
v_session v$session.sid%TYPE;
e_deadlock exception;
pragma exception_init (e_deadlock, -60);
begin
select sys_context('USERENV', 'SID')
into v_session
from dual;
update t1
set session_id = v_session
where key = p_key1;
dbms_system.ksdwrt(2, to_char(sysdate, 'YYYY-MM-DD HH24:MI:SS')
|| ' Session ' || v_session
|| ': First update key = ' || p_key1);
dbms_system.ksdwrt(2, to_char(sysdate, 'YYYY-MM-DD HH24:MI:SS')
|| ' Sleeping...');
dbms_lock.sleep(10);
update t1
set session_id = v_session
where key = p_key2;
dbms_system.ksdwrt(2, to_char(sysdate, 'YYYY-MM-DD HH24:MI:SS')
|| ' Session ' || v_session
|| ': Second update key = ' || p_key2);
dbms_system.ksdwrt(2, to_char(sysdate, 'YYYY-MM-DD HH24:MI:SS')
|| ' Session ' || v_session || ': Writing log');
insert into ora60_log
values (v_session, 'SUCCESS', NULL, sysdate);
commit;
exception
when e_deadlock
then v_err_code := SQLCODE;
dbms_system.ksdwrt(2, to_char(sysdate, 'YYYY-MM-DD HH24:MI:SS')
|| ' Session ' || v_session
|| ': Exiting DEADLOCK');
insert into ora60_log
values (v_session, 'DEADLOCK', v_err_code, sysdate);
commit;
end;
/Let’s take a look at what each piece of the stored procedure does.
create or replace procedure ora60 (
p_key1 in t1.key%TYPE
, p_key2 in t1.key%TYPE)The procedure accepts two input variables, which it uses to perform sequential updates.
e_deadlock exception;
pragma exception_init (e_deadlock, -60);This defines the deadlock exception, e_deadlock, and assigns it to the ORA-60 condition.
select sys_context('USERENV', 'SID')
into v_session
from dual;The select sys_context captures the session_id to identify the session responsible for the update.
dbms_system.ksdwrt(2, to_char(sysdate, 'YYYY-MM-DD HH24:MI:SS')
...The dbms_system.ksdwrt system built-in allows us to write information to the database alert log. We’ll use this to show what step (and at what time) is running and gives real-time visibility into what’s happening in the code.
update t1
set session_id = v_session
where key = p_key1;
...
dbms_lock.sleep(10);
update t1
set session_id = v_session
where key = p_key2;This is the heart of the procedure and what creates the deadlock. The first update sets the table’s session_id for the first key value passed to the procedure, then sleeps for 10 seconds. The second update does the same, for the second key value passed to the procedure.
We create a deadlock by running this procedure with two key values in different order. The dbms_lock.sleep delays the second update long enough to execute the procedure in another session, producing the deadlock.
Finally:
exception
when e_deadlock
then v_err_code := SQLCODE;
dbms_system.ksdwrt(2, to_char(sysdate, 'YYYY-MM-DD HH24:MI:SS')
|| ' Session ' || v_session
|| ': Exiting DEADLOCK');
insert into ora60_log
values (v_session, 'DEADLOCK', v_err_code, sysdate);
commit;
end;The exception handler writes a message to the alert log and inserts a diagnostic record into the logging table.
Create a Deadlock
From two separate sessions, run the procedure:
-- Session 1:
exec ora60(1, 2);-- Session 2:
exec ora60(2, 1);- Session 1 updates the row with
key = 1and sleeps 10 seconds. - Session 2 updates the row with
key = 2and sleeps 10 seconds. - Session 1 attempts to update the row with
key = 2and encountersenq: TX - contention. - Session 2 attempts to update the row with
key = 1, creating a deadlock.
In the alert log we see:
2023–08–25T14:35:30.256461+00:00
2023–08–25 14:35:30 Session 281: First update key = 1
2023–08–25 14:35:30 Sleeping...
2023–08–25T14:35:31.107752+00:00
2023–08–25 14:35:31 Session 20: First update key = 2
2023–08–25 14:35:31 Sleeping...
2023–08–25T14:35:43.325268+00:00
Errors in file
/u01/app/oracle/diag/rdbms/orclcdb/ORCLCDB/trace/ORCLCDB_ora_19388.trc:
2023–08–25T14:35:43.578394+00:00
ORA-00060: Deadlock detected. See Note 60.1 at My Oracle Support for
Troubleshooting ORA-60 Errors. More info in file
/u01/app/oracle/diag/rdbms/orclcdb/ORCLCDB/trace/ORCLCDB_ora_19388.trc.
2023–08–25T14:35:43.578811+00:00
2023–08–25 14:35:43 Session 281: Exiting DEADLOCK
2023–08–25T14:35:43.580515+00:00
2023–08–25 14:35:43 Session 20: Second update key = 1
2023–08–25 14:35:43 Session 20: Writing logBoth sessions completed successfully:
-- Session 1
SQL> exec ora60(1, 2);
PL/SQL procedure successfully completed.-- Session 2
SQL> exec ora60(2, 1);
PL/SQL procedure successfully completed.There are no blocking sessions:
select 'Blocking:'
, s1.username
, s1.machine
, s1.sid
, 'Blocked:'
, s2.username
, s2.machine
, s2.sid
from v$lock l1
, v$session s1
, v$lock l2
, v$session s2
where s1.sid = l1.sid
and s2.sid = l2.sid
and l1.block = 1
and l2.request > 0
and l1.id1 = l2.id1
and l2.id2 = l2.id2;
no rows selectedSince session 1 (SID 281) raised the deadlock exception, we assume that it failed and that session 2 (with SID 20) succeeded. If that’s true, the data in the table should look like this:
KEY VAL1 SESSION_ID
--- --------- ----------
1 1 20
2 1 20If so, it means that session 2 (with SID 20) successfully updated both rows.
From a third session, the log table seems to confirm this. There’s a record for the deadlock raised from session 1, and another for the successful update performed in session 2:
SQL> select * from ora60_log;
ERR_SOURCE ERR_EXCEPT ERR_CODE ERR_DATE
------------------ ------------------ --------------- --------------
281 DEADLOCK -60 25-AUG-23
20 SUCCESS 25-AUG-23And indeed, the data in table T1 appears to be correct:
SQL> select * from t1;
KEY VAL1 SESSION_ID
--- --------- ----------
1 1 20
2 1 20What Does the Test Confirm?
The result appears to be correct because it matches the test we performed. We updated a column with a scalar and saw the expected value, which might lead us to believe that the exception handler worked.
But did it? Is this a valid test?
Let’s change the stored procedure slightly by altering the two update statements:
update t1
set val1 = val1 + 10
, session_id = v_session
where key = p_key1;
...
dbms_lock.sleep(10);
update t1
set val1 = val1 + 20
, session_id = v_session
where key = p_key2;Revert the data to its original state:
truncate table ora60_log;
update t1
set val1 = 1
, val2 = NULL;
commit;Now, rerun the demo. The exception handler still works, and there are no locks. If session 1 failed and session 2 succeeded, we should see the following result, with 20 added to key = 1 and 10 added to key = 2:
SQL> select * from t1;
KEY VAL1 SESSION_ID
----- --------- -----------------
1 21 20
2 11 20However, the real contents of the table do not match. The exception handler corrupted row 1:
SQL> select * from t1;
KEY VAL1 SESSION_ID
---- ----------- ---------------
1 31 20
2 11 20Why?
Session 1 incremented the value for key = 1 by 10, then encountered the deadlock and raised the exception handler. When the exception handler added a row to the logging table and issued a commit, it also committed the update of the row with key = 1!
There are ways of solving this, including:
- Adding a
rollbackto the start of the exception handler. - Embedding the logging within an
autonomous_transaction pragma.
But this simple scenario doesn’t reflect the complexity of real applications, and these solutions have ramifications for more involved code.
- Often, the purpose of an exception handler, particularly in complex packages or procedures, is to fix the problem and re-execute the failed block, rather than undoing (and retrying) a full transaction. A
rollbackwould act on all DML performed in the procedure—including statements that weren’t involved in the deadlock. A deadlock exception must, therefore, fail the complete transaction or jeopardize atomicity. - Using
autonomous_transactionto isolate logging probably wouldn’t add to concurrency, but it doesn’t solve the data issues above. There must still be a rollback. And don’t forget that we only saw the “bad data” thanks to thecommitrequired to log the results to a table! - Complete tests that anticipate every possible condition are important. The first example seemed to demonstrate a working exception handler. The deadlock was cleared, the
updateworked, and the results matched expectations. It isn’t always easy to see the difference between assumed and real test success.
The example procedure created the narrowest possible concurrency protection possible in Oracle—exclusive locks on two unique rows in a single table. The depth and severity grow quickly when deadlocks involve:
- Multiple rows;
- Multiple tables;
- Table locks;
- Nested PL/SQL packages, procedures, and functions;
- Hierarchal PL/SQL blocks (
begin ... begin ... [exception] end; [exception] end;); - “Artificial” locks (e.g.,
lock table,select for update [nowait],set transaction,savepoint); - Implicit commits (e.g.,
truncate); execute immediatestatements;- Triggers;
- Ad hoc SQL; etc.
Each of these also complicates testing and affects how and where to raise exceptions. What seemed like a straightforward fix can quickly become a coding nightmare! Rather than engineering solutions that second-guess Oracle concurrency, it may be better to address the root cause — the logic that causes the deadlocking in the first place!




SUBMIT YOUR COMMENT